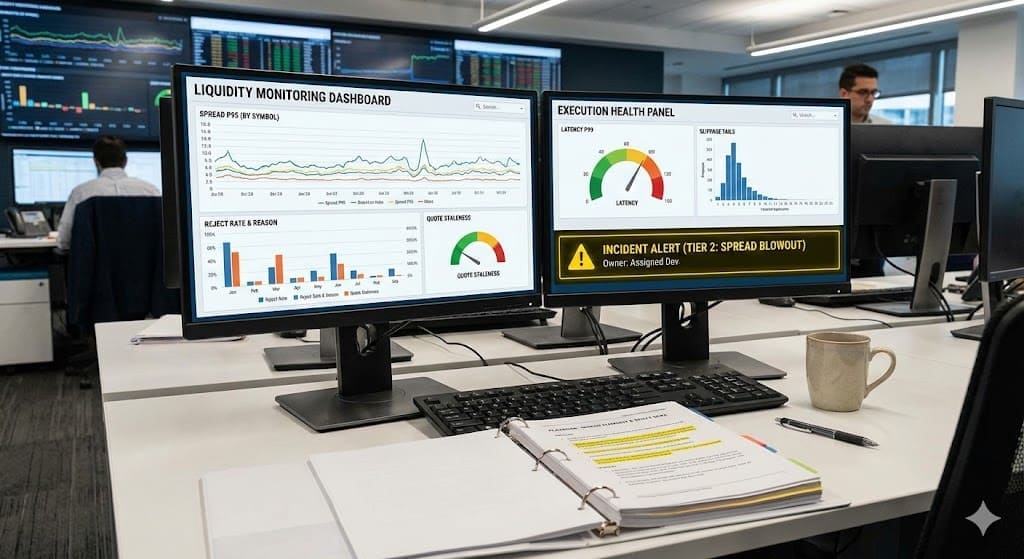
Problemas de execução raramente se anunciam de forma educada. Um minuto a plataforma parece normal. No próximo minuto, os spreads se ampliam, as ordens são rejeitadas, e os tickets de suporte começam a se acumular com a mesma reclamação formulada de vinte maneiras diferentes. É exatamente aqui que uma mentalidade de monitoramento se paga.
O objetivo não é a perfeição. O objetivo é a visibilidade e controle: detectar a degradação cedo, identificar a causa rapidamente e responder de forma consistente. Em termos práticos, uma configuração de corretagem madura monitora todas as fontes de liquidez e trata a saúde da liquidez como um sistema vivo, não uma caixa de seleção de fornecedor estático.
“Se você não pode explicar um minuto completo, você não tem um processo de execução, você tem um debate.”
Este guia detalha a cadeia de execução, a pilha de monitoramento que realmente ajuda em dias movimentados, e playbooks simples que protegem tanto os clientes quanto as equipes internas.
A cadeia de execução em 90 segundos
Cada ordem viaja através de uma cadeia de componentes que introduzem risco, latência e potenciais pontos de falha.
Em um nível alto, você geralmente tem:
- fontes de preços produzindo cotações
- lógica de agregação ou roteamento selecionando um caminho
- verificações de risco aprovando ou rejeitando a ordem
- uma ponte ou gateway enviando a ordem para baixo
- locais de liquidez respondendo com um preenchimento, rejeição ou preenchimento parcial
- sistemas pós-negociação armazenando logs e produzindo relatórios
Quando as pessoas falam sobre execução de ordens de negociação, elas frequentemente se concentram no preço final do preenchimento. Em operações, execução é mais ampla: integridade de cotação, disciplina de roteamento, consistência de latência, clareza de rejeição e trilhas de evidências.
Onde a execução comumente falha
Estes são os cenários mais frequentes de “parece quebrado” que aparecem em filas de suporte reais:
- Explosão de spreads fora das janelas de notícias esperadas
- Cotações obsoletas onde o preço parece válido mas está desatualizado
- Picos de rejeição ligados a uma rota ou grupo de símbolos
- Picos de latência que transformam ordens normais de mercado em eventos de derrapagem
- Preenchimentos parciais que surpreendem os clientes e complicam a cobertura
- Derrapagem unilateral que desencadeia reclamações de justiça
Se você monitorar apenas spreads médios e latência média, perderá os momentos exatos que criam 80% das reclamações.
O monitoramento de liquidez é mais difícil do que parece
Muitas equipes acham que estão monitorando a liquidez porque podem ver “spread atual” e “preço atual”. Isso está mais próximo de um papel de parede ao vivo do que de um monitoramento.
A liquidez é dinâmica. Ela muda por:
- sessão (Ásia vs Europa vs EUA)
- grupo de instrumentos (principais vs secundários vs metais)
- regime de mercado (faixa, tendência, volatilidade orientada por eventos)
- comportamento do local (profundidade, rejeições, timeouts)
- carga interna (verificações de risco, bancos de dados, rede)
Uma abordagem de monitoramento limpa assume variabilidade e constrói bases que a refletem.
“Monitoramento não é observar um número. Monitoramento é saber quando um número é anormal para este momento.”
Ver o problema não é o mesmo que agir sobre ele
Um painel pode mostrar que algo está errado e ainda ser inútil se:
- alertas não têm proprietários
- limiares são arbitrários
- a equipe discute sobre a causa raiz toda vez
- a única resposta é “desligue” ou “não faça nada”
Um programa de monitoramento torna-se valioso quando transforma sinais em decisões.
A pilha de monitoramento que funciona em dias movimentados
Uma pilha de monitoramento prático tem camadas. Cada camada responde a uma pergunta diferente e, juntas, explicam a maioria dos incidentes rapidamente.
Camada 1: Integridade de preço e saúde de cotação
É aqui que um monitor de spread pertence, junto com verificações de frescor de cotação.
Monitorar:
- percentis de spread (p50 e p95, não apenas médias)
- frequência de atualização de cotação (ticks por minuto)
- taxa de cotação obsoleta (cotações mais antigas que a tolerância)
- divergência de preço entre fontes (detecção de outliers)
Por que isso importa: Se as cotações estão ruins, tudo a jusante parece falha de execução mesmo quando o roteamento está bem.
Camada 2: Saúde do fluxo de ordens e resultados de roteamento
É aqui que você mede a canalização de execução de ordens de negociação.
Monitorar:
- taxa de rejeição por grupo de símbolos e rota
- categorias de razões de rejeição (liquidez, risco, plataforma)
- percentis de latência de preenchimento (p95 e p99)
- taxa de preenchimento parcial por balde de tamanho
- taxa de timeout e comportamento de tentativa
Esta camada é a melhor leitura inicial sobre velocidade e estabilidade de negociação, porque mostra se o sistema se comporta normalmente sob carga, não apenas durante períodos calmos.
Camada 3: Exposição e concentração
Incidentes de liquidez tornam-se incidentes de corretagem quando o risco se concentra.
Monitorar:
- exposição por símbolo, coorte e grupo de parceiros
- velocidade de estresse de margem (contas próximas ao limite)
- concentração por rota (muito fluxo em um caminho)
- assinaturas de lucro anormais que sugerem fluxo tóxico
Uma tabela inicial de sinais, métricas e intenção de ação
| Sinal | Métrica para monitorar | Segmentar por | Intenção primária |
| Spreads se ampliando | p95 spread vs base de referência | símbolo, sessão | detectar a redução de liquidez cedo |
| Cotações envelhecendo | taxa de cotação obsoleta | fornecedor, símbolo | evitar disputas de “preço ruim” |
| Ordens sendo rejeitadas | taxa de rejeição + códigos de razão | rota, símbolo | isolar problemas de roteamento ou local |
| Preenchimentos se degradando | cauda de derrapagem p95 | tipo de ordem, tamanho | proteger a experiência do cliente |
| Sistema desacelerando | latência p99 | rota, sessão | proteger velocidade e estabilidade de negociação |
| Risco aumentando | concentração de exposição | coorte, parceiro | prevenir colapsos e reações tardias |
Esta tabela é intencionalmente pequena. O monitoramento excessivo cria fadiga de alerta.
Desenhando um monitor de spread que seja acionável
Um monitor de spread é útil apenas se responder a uma pergunta: “Este comportamento de spread é normal para este mercado e esta hora?”
Percentis superam médias
Médias são confortáveis. Percentis são honestos.
Acompanhe:
- p50 spread: condições típicas
- p95 spread: condições de estresse que os clientes percebem
- máximo spread: outliers que valem investigação
Depois, base por sessão. Um p95 spread às 3:00 a.m. pode ser normal para um instrumento e alarmante para outro.
“O p95 é onde a confiança é ganha ou perdida, porque é onde os traders lembram da dor.”
Vincule spreads a outros sinais
Spreads sozinhos podem se ampliar por razões benignas. A abordagem mais útil correlaciona:
- spread piorando em p95
- mais aumento na taxa de rejeição
- mais aumento na obsolescência de cotação
- ou deterioração da latência p99
Quando dois ou três se movem juntos, você tem um incidente real, não ruído.
Um conjunto simples de regras de spread que você pode realmente executar
| Condição | Exemplo de estilo de limiar | Resposta típica |
| Desvio leve | p95 spread > 1.5x base por 10 min | notificar operações, observar de perto |
| Incidente confirmado | p95 > 2x base mais pico de rejeição | revisão de rota, filtros de proteção |
| Estresse severo | outliers de spread máximo mais obsolescência | congelar símbolos afetados ou apertar verificações de risco |
| Transição de sessão | janela conhecida (abertura/fechamento) | aplicar regras de playbook temporárias |
Os multiplicadores exatos dependem de seus instrumentos e locais. A estrutura é o que importa.
Transformando dashboards em decisões com playbooks
Quando os spreads aumentam ou os picos de rejeição ocorrem, o pior cenário é a improvisação. Um playbook torna a resposta consistente, auditável e mais rápida.
Playbook 1: Explosão de spread
Desencadeador
- p95 spread excede a faixa de base por 10 minutos
- mais ou aumento de obsolescência ou pico de rejeição
Primeiras ações
- confirmar saúde de cotações: taxa de tick, lacunas de feed, outliers
- comparar comportamento de spread entre fontes de liquidez
- verificar se o problema está isolado a um grupo de símbolos ou rota
Opções de mitigação
- aplicar filtros de spread de proteção onde a política permite
- redirecionar o fluxo longe de fontes degradadas
- apertar temporariamente os limites de tamanho nos símbolos afetados
Comunicação
- enviar uma nota interna curta para suporte com linguagem simples:
- símbolos afetados
- comportamento esperado (spreads mais amplos, possíveis rejeições)
- tempo estimado de revisão
- símbolos afetados
Playbook 2: Pico de rejeição
Desencadeador
- taxa de rejeição dobra a base para um grupo de símbolos em uma janela curta
Primeiras ações
- quebrar rejeições em categorias:
- rejeição de liquidez
- rejeição de risco
- rejeição de plataforma ou validação
- rejeição de liquidez
- isolar por resposta de rota e local
- verificar timeouts e comportamento de tentativa
Opções de mitigação
- redirecionar uma parte do fluxo
- aplicar limitação para tráfego em explosão
- ajustar temporariamente as verificações de risco se estiverem causando falsas rejeições
Hábito crítico
- nunca trate “pico de rejeição” como um único problema
- geralmente são várias causas sobrepostas
Playbook 3: Pico de latência afetando velocidade e estabilidade de negociação
Desencadeador
- latência p99 aumenta significativamente em relação à base durante a sessão de pico
Primeiras ações
- separate network latency from processing latency
- verificar o tempo de processamento de verificações de risco sob carga
- verificar contenção de banco de dados ou gargalos de log
Opções de mitigação
- reduzir tarefas síncronas não críticas no caminho de execução
- deslocar consultas de relatórios pesados para fora dos sistemas críticos de execução
- ativar uma política de modo seguro para janelas de alta volatilidade
“Um playbook é uma decisão que você tomou em condições calmas para não tomar uma decisão pior sob pressão.”
Uma tabela compacta de playbooks para referência rápida
| Incidente | Indicador rápido | Proprietário | Duas primeiras ações |
| Explosão de spread | faixa de p95 spread quebrada | líder de negociação ou operações | validar feeds, comparar fontes |
| Pico de rejeição | picos de rejeição, códigos de razão mudam | operações de execução | segmentar por rota, redirecionar fração |
| Cotações obsoletas | aumento da razão de obsolescência | proprietário de dados de mercado | isolar feed, aplicar salvaguardas |
| Pico de latência | aumento de p99 de latência | operações de plataforma | encontrar gargalo, reduzir carga síncrona |
| Evento de cauda de derrapagem | derrubada de p95 piora | execução + risco | correlacionar com spreads e latência |
Se você não conseguir atribuir um proprietário, o incidente será “de todos”, o que significa não ser de ninguém.
Complicações multi-ativos que você deve esperar
O monitoramento se torna mais importante à medida que você adiciona instrumentos ou classes de ativos, porque o comportamento muda.
Janelas de estresse diferem por mercado
- FX: transições de sessão e lançamentos de notícias
- Índices: explosões de abertura e fechamento
- Commodities: relatórios agendados e reavaliação súbita
- Ações: leilões, pausas, bolsões de liquidez
Um bom sistema de monitoramento armazena bases de referência separadas por:
- classe de ativo
- grupo de símbolos
- janela de sessão
Caso contrário, seus alertas serão ruidosos demais ou cegos demais.
Execução e liquidez não são o mesmo problema em todos os lugares
Em alguns mercados, o alargamento de spread é normal na abertura. Em outros, sinaliza um problema de feed. O monitoramento precisa de contexto, não apenas limiares.
Visibilidade de coorte e rota: a atualização de escala que a maioria das equipes pula
Incidentes de execução tornam-se dolorosos quando você não consegue responder:
- “Isso vem de uma coorte de parceiros?”
- “Uma rota está produzindo a maioria das rejeições?”
- “As contas recém-financiadas estão gerando a maioria das reclamações?”
- “Um grupo de símbolos está gerando estresse de margem?”
A segmentação por coorte é uma maneira prática de prevenir restrições amplas e contundentes que penalizam o bom fluxo.
Um modelo simples de segmentação:
- recém-financiado (primeiros 30 dias)
- varejo ativo (volume constante)
- VIP
- coortes de parceria (grupos de IB, afiliados)
- cluster de alta disputa (problemas recorrentes)
“A escala quebra quando você gerência todos da mesma maneira, mesmo que o comportamento não seja o mesmo.”
Trilhas de evidências que reduzem disputas e dores de conformidade
Monitoramento não é apenas sobre prevenção. É também sobre velocidade de explicação.
Um “pacote de evidências de execução” mínimo deve incluir:
- carimbo de tempo do pedido e carimbo de recebimento
- instantâneo de cotação no momento do pedido
- rota e resposta do local
- carimbo de tempo de preenchimento e discriminação de latência
- estado do spread na entrada
- dicionário de códigos de razões de rejeição
Se o suporte puder acessar isso rapidamente, as escalonamentos diminuem e a equipe para de adivinhar.
Um plano de implementação de 30 dias que evita o caos
Você pode melhorar o monitoramento sem reconstruir toda a sua pilha. O truque é priorizar sinais, propriedade e bases de referência.
Semana 1: Bases de referência e definições
- definir grupos de símbolos e sessões
- basear spreads, rejeições, percentis de latência durante 14 dias
- padronizar códigos de razões de rejeição
Ssegunda semana: Monitor de spread e categorização de alertas
- implementar rastreamento de p50 e p95 spread por sessão
- definir níveis de alerta (informativo, ação, escalonamento)
- atribuir responsáveis e expectativas de reconhecimento
Semana 3: Manuais de Operação e simulações
- escrever três manuais de operação de uma página (propagação, rejeições, latência)
- executar uma simulação com suporte, operações e risco
- refinar os limiares para reduzir falsos positivos
Semana 4: Segmentação e relatórios
- adicionar segmentação de coorte e vistas por nível de rota
- criar uma revisão semanal:
- incidentes
- causas raiz
- ações e responsáveis
- ajustes de limites
- incidentes
O objetivo é uma melhoria constante, não um “lançamento de monitoramento” único.
Erros que sabotam programas de monitoramento de liquidez
- Monitorar apenas médias e perder eventos extremos
- Sem referenciais de sessão, tornando alertas sem significado
- Alertas em excesso, levando à fadiga e sinais ignorados
- Falta de responsabilidade, então a resposta depende de quem está online
- Sem manuais de operação, então cada incidente vira uma reunião
- Sem pacote de evidências, então disputas tornam-se discussões
Se você corrigir apenas uma coisa, corrija referenciais e responsabilidade. Todo o resto se constrói a partir disso.
Próximo passo antes do FAQ
Se você quer um monitoramento que realmente ajude, comece com um referencial de 14 dias para spreads (p50 e p95), rejeições e latência p99 por sessão e grupo de símbolos. Depois, construa um monitor de spread que correlaciona com picos de rejeição e obsolescência de cotações, e escreva três manuais de operação de uma página para que a resposta se torne consistente. Se você compartilhar seus principais instrumentos negociados, horários de maior movimento e o tipo de reclamação mais comum, envie esse instantâneo para sua equipe de operações e use-o para pilotar uma tabela de alertas mais precisa e um pacote de evidências que protege execução de ordens de negociação e melhora velocidade e estabilidade de negociação sem adicionar ruído.
FAQ
Por que monitorar todas as fontes de liquidez é importante?
Porque os problemas costumam ser isolados: um local amplia os spreads, uma rota rejeita, uma fonte fica inativa. Sem visibilidade entre fontes, as equipes reagem tarde ou culpam o componente errado.
O que um monitor de spreads deve rastrear além do spread atual?
Percentuais por sessão (p50 e p95), além de outliers e duração. O objetivo é detectar comportamento anormal, não ficar olhando para um número em movimento.
Qual métrica de execução prevê reclamações de clientes de forma mais confiável?
Eventos extremos de desvio e picos de rejeição. As médias podem parecer boas enquanto o comportamento extremo gera a maioria das disputas e frustrações.
Como a fadiga de alerta pode ser reduzida?
Use referenciais de sessão, alerte apenas em desvios sustentados e categorize alertas por gravidade. Cada alerta deve ter um responsável e uma lista de verificação de primeira ação.
Melhorar o monitoramento de liquidez automaticamente melhora as execuções?
Melhora a detecção e resposta, o que reduz a duração e o impacto dos incidentes. Melhorias nas execuções geralmente vêm das ações que você toma uma vez que o monitoramento revela a causa.
Qual é o mínimo de evidências necessárias para resolver rapidamente uma disputa de execução?
Carimbos de tempo de ordem, instantâneo de cotação, caminho de roteamento, resposta do local, análise de latência e um dicionário claro de motivos de rejeição se uma rejeição ocorreu.