


Los problemas de ejecución rara vez se anuncian con cortesía. Un minuto la plataforma se siente normal. Al siguiente minuto, los márgenes se ensanchan, las órdenes son rechazadas y las solicitudes de soporte comienzan a acumularse con la misma queja expresada de veinte formas diferentes. Aquí es exactamente donde una mentalidad de monitoreo se paga por sí misma.
El objetivo no es la perfección. El objetivo es la visibilidad y el control: detectar la degradación temprano, identificar la causa rápidamente y responder de manera consistente. En términos prácticos, una configuración madura de corretaje monitorea todas las fuentes de liquidez y trata la salud de la liquidez como un sistema en vivo, no como una lista de verificación de proveedores estática.
“Si no puedes explicar un minuto completo, no tienes un proceso de ejecución, tienes un debate.”
Esta guía desglosa la cadena de ejecución, la pila de monitoreo que realmente ayuda en días ocupados, y libros de jugadas simples que protegen tanto a los clientes como a los equipos internos.
La cadena de ejecución en 90 segundos
Cada orden viaja a través de una cadena de componentes que cada uno introduce riesgo, latencia y posibles puntos de falla.
A un alto nivel, usualmente tienes:
- fuentes de precios produciendo cotizaciones
- lógica de agregación o enrutamiento seleccionando un camino
- controles de riesgo aprobando o rechazando la orden
- un puente o pasarela enviando la orden aguas abajo
- lugares de liquidez respondiendo con una completación, rechazo o llenado parcial
- sistemas post-transacción almacenando registros y generando informes
Cuando la gente habla de ejecución de órdenes de trading, a menudo se centran en el precio final de llenado. En operaciones, la ejecución es más amplia: integridad de las cotizaciones, disciplina en el enrutamiento, consistencia de latencia, claridad en los rechazos y trazabilidad.
Donde la ejecución comúnmente falla
Estos son los escenarios más frecuentes de “se siente roto” que aparecen en colas de soporte reales:
- Estallidos de márgenes fuera de las ventanas de noticias esperadas
- Obsolescencia de cotizaciones donde el precio parece válido pero está desactualizado
- Aumentos de rechazos vinculados a una ruta o grupo de símbolos
- Picos de latencia que convierten las órdenes de mercado normales en eventos de deslizamiento
- Llenados parciales que sorprenden a los clientes y complican la cobertura
- Deslizamiento unilateral que desencadena quejas de equidad
Si solo monitoreas los márgenes promedio y la latencia promedio, perderás los momentos exactos que generan el 80 por ciento de las quejas.
El monitoreo de liquidez es más difícil de lo que parece
Muchos equipos piensan que están monitoreando la liquidez porque pueden ver el “margen actual” y el “precio actual”. Eso está más cerca de un fondo de pantalla en vivo que de un monitoreo.
La liquidez es dinámica. Cambia según:
- sesión (Asia vs Europa vs EE.UU.)
- grupo de instrumentos (mayores vs menores vs metales)
- régimen de mercado (rango, tendencia, volatilidad impulsada por eventos)
- comportamiento del centro (profundidad, rechazos, tiempos de espera)
- carga interna (controles de riesgo, bases de datos, red)
Un enfoque de monitoreo limpio asume variabilidad y construye líneas base que lo reflejen.
“Monitorear no es ver un número. Monitorear es saber cuándo un número es anormal para este momento.”
Ver el problema no es lo mismo que actuar sobre él
Un tablero puede mostrar que algo está mal y aún así ser inútil si:
- las alertas no tienen propietarios
- los umbrales son arbitrarios
- el equipo discute sobre la causa raíz cada vez
- la única respuesta es “apagar” o “no hacer nada”
Un programa de monitoreo se vuelve valioso cuando convierte las señales en decisiones.
La pila de monitoreo que funciona en días ocupados
Una pila de monitoreo práctica tiene capas. Cada capa responde a una pregunta diferente, y juntas explican la mayoría de los incidentes rápidamente.
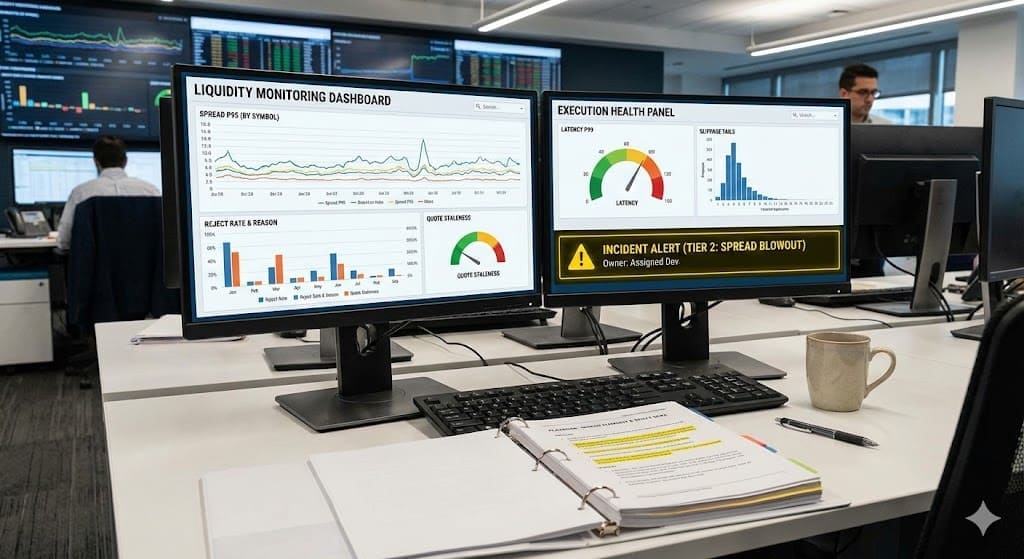
Capa 1: Integridad de precios y salud de cotizaciones
Aquí es donde un monitor de márgenes pertenece, junto con comprobaciones de frescura de cotizaciones.
Monitorear:
- percentiles de márgenes (p50 y p95, no solo promedios)
- frecuencia de actualización de cotizaciones (ticks por minuto)
- ratio de cotizaciones obsoletas (cotizaciones más antiguas que la tolerancia)
- divergencia de precios entre fuentes (detección de valores atípicos)
Por qué importa: Si las cotizaciones son poco saludables, todo lo que sigue parece una falla de ejecución incluso cuando el enrutamiento está bien.
Capa 2: Salud del flujo de órdenes y resultados de enrutamiento
Aquí es donde mides la infraestructura de ejecución de órdenes de trading.
Monitorear:
- tasa de rechazos por grupo de símbolos y ruta
- categorías de razones de rechazo (liquidez, riesgo, plataforma)
- percentiles de latencia de llenado (p95 y p99)
- tasa de llenados parciales por tamaño de bloque
- tasa de tiempos de espera y comportamiento de reintento
Esta capa es la mejor lectura anticipada sobre velocidad y estabilidad del trading, porque muestra si el sistema se comporta normalmente bajo carga, no solo durante períodos tranquilos.
Capa 3: Exposición y concentración
Los incidentes de liquidez se convierten en incidentes de corretaje cuando el riesgo se concentra.
Monitorear:
- exposición por símbolo, cohorte y grupo de socios
- velocidad de tensión de margen (cuentas próximas al margen de cierre)
- concentración por ruta (demasiado flujo en un solo camino)
- firmas de ganancias anormales que sugieren flujo tóxico
Una tabla inicial de señales, métricas e intención de acción
| Señal | Métrica a observar | Segmentar por | Intención primaria |
| Márgenes expandiéndose | p95 de margen frente a la línea base | símbolo, sesión | detectar adelgazamiento de liquidez temprano |
| Cotizaciones envejeciendo | ratio de cotizaciones obsoletas | proveedor, símbolo | evitar disputas por “mal precio” |
| Órdenes rechazadas | tasa de rechazos + códigos de razón | ruta, símbolo | aislar problemas de enrutamiento o de centros |
| Llenados degradándose | cola de deslizamiento p95 | tipo de orden, tamaño | proteger la experiencia del cliente |
| Sistema ralentizándose | latencia p99 | ruta, sesión | proteger la velocidad y estabilidad del trading |
| Riesgo acumulándose | concentración de exposición | cohorte, socio | prevenir crisis y reacciones tardías |
Esta tabla es intencionadamente pequeña. El exceso de monitoreo crea fatiga de alertas.
Diseñando un monitor de márgenes que sea accionable
Un monitor de márgenes es útil solo si responde a una pregunta: “¿Es este comportamiento de márgenes normal para este mercado y esta hora?”
Los percentiles vencen a los promedios
Los promedios son reconfortantes. Los percentiles son honestos.
Seguimiento:
- p50 de márgenes: condiciones típicas
- p95 de márgenes: condiciones de estrés que los clientes notan
- margen máximo: valores atípicos que valen la pena investigar
Luego establece una línea base por sesión. Un margen p95 a las 3:00 a.m. puede ser normal para un instrumento y alarmante para otro.
“El p95 es donde se gana o se pierde la confianza, porque es donde los traders recuerdan el dolor.”
Vincula márgenes a otras señales
Los márgenes solos pueden ampliarse por razones benignas. El enfoque más útil correlaciona:
- margen p95 empeorando
- más tasa de rechazos aumentando
- más obsolescencia de cotizaciones aumentando
- o degradación de latencia p99
Cuando dos o tres se mueven juntos, tienes un incidente real, no ruido.
Un conjunto simple de reglas de márgenes que realmente puedes ejecutar
| Condición | Estilo de umbral de ejemplo | Respuesta típica |
| Desviación leve | p95 de margen > 1.5x línea base por 10 min | notificar a operaciones, observar de cerca |
| Incidente confirmado | p95 > 2x línea base más pico de rechazos | revisión de ruta, filtros protectores |
| Estrés severo | valores atípicos de margen máximo más obsolescencia | congelar símbolos afectados o ajustar controles de riesgo |
| Transición de sesión | ventana conocida (apertura/cierre) | aplicar reglas de libro de jugadas temporales |
Los multiplicadores exactos dependen de tus instrumentos y centros. La estructura es lo que importa.
Convertir tableros en decisiones con libros de jugadas
Cuando los márgenes se disparan o los rechazos aumentan, el peor de los casos es la improvisación. Un libro de jugadas hace que la respuesta sea consistente, auditable y más rápida.
Libro de jugadas 1: Estallido de margen
Detonante
- p95 de margen excede la banda base por 10 minutos
- más aumento de obsolescencia o pico de rechazos
Primeras acciones
- confirmar la salud de las cotizaciones: tasa de ticks, brechas en el feed, valores atípicos
- comparar el comportamiento de los márgenes entre fuentes de liquidez
- verificar si el problema está aislado a un grupo de símbolos o ruta
Opciones de mitigación
- aplicar filtros protectores de márgenes donde la política lo permita
- redirigir el flujo lejos de las fuentes degradadas
- ajustar temporalmente los límites de tamaño en los símbolos afectados
Comunicación
- enviar una nota interna corta a soporte con un lenguaje claro:
- símbolos afectados
- comportamiento esperado (márgenes más amplios, posibles rechazos)
- tiempo estimado de revisión
- símbolos afectados
Libro de jugadas 2: Pico de rechazos
Detonante
- la tasa de rechazos duplica la línea base para un grupo de símbolos en un breve período
Primeras acciones
- desglosar rechazos en categorías:
- rechazo de liquidez
- rechazo de riesgo
- rechazo de plataforma o validación
- rechazo de liquidez
- aislar por respuesta de ruta y centro
- verificar los tiempos de espera y comportamiento de reintento
Opciones de mitigación
- redirigir una parte del flujo
- aplicar limitación para tráfico intenso
- ajustar temporalmente los controles de riesgo si están causando rechazos falsos
Hábito crítico
- nunca tratar “pico de rechazos” como un solo problema
- generalmente son múltiples causas superpuestas
Libro de jugadas 3: Pico de latencia que afecta la velocidad y estabilidad del trading
Detonante
- la latencia p99 aumenta significativamente frente a la línea base durante la sesión máxima
Primeras acciones
- separate network latency from processing latency
- verificar el tiempo de procesamiento de controles de riesgo bajo carga
- verificar la contención de base de datos o cuellos de botella en los registros
Opciones de mitigación
- reducir tareas síncronas no críticas en la ruta de ejecución
- desplazar consultas de informes pesados fuera de sistemas críticos de ejecución
- activar una política de modo seguro para ventanas de alta volatilidad
“Un libro de jugadas es una decisión que tomaste en condiciones tranquilas para no tomar una peor decisión bajo presión.”
Una tabla de libro de jugadas compacta para una referencia rápida
| Incidente | Indicador rápido | Propietario | Primeras dos acciones |
| Estallido de margen | brecha de banda de margen p95 | responsable de operaciones o negociación | validar feeds, comparar fuentes |
| Pico de rechazos | rechazos suben, cambian los códigos de razón | operaciones de ejecución | segmentar por ruta, redirigir fracción |
| Cotizaciones obsoletas | aumento del ratio de obsolescencia | propietario de datos de mercado | aislar feed, aplicar salvaguardas |
| Pico de latencia | aumento de latencia p99 | operaciones de plataforma | encontrar cuello de botella, reducir carga síncrona |
| Evento de cola de deslizamiento | desempeño de cola de deslizamiento p95 empeora | ejecución + riesgo | correlacionar con márgenes y latencia |
Si no puedes asignar un propietario, el incidente será “propiedad de todos”, lo que significa que no será propiedad de nadie.
Complicaciones multi-activos que debes esperar
El monitoreo se vuelve más importante a medida que agregas instrumentos o clases de activos, porque el comportamiento cambia.
Las ventanas de estrés difieren según el mercado
- FX: transiciones de sesiones y comunicados de noticias
- Índices: ráfagas de apertura y cierre
- Commodities: informes programados y reajustes repentinos de precios
- Acciones: subastas, pausas, bolsas de liquidez
Un buen sistema de monitoreo almacena líneas base separadas por:
- clase de activo
- grupo de símbolos
- ventana de sesión
De lo contrario, tus alertas serán demasiado ruidosas o demasiado ciegas.
La ejecución y la liquidez no son el mismo problema en todas partes
En algunos mercados, el ensanchamiento de márgenes es normal al abrir. En otros, indica un problema de feed. El monitoreo necesita contexto, no solo umbrales.
Visibilidad de cohorte y ruta: la actualización de escala que la mayoría de los equipos omite
Los incidentes de ejecución se vuelven dolorosos cuando no puedes responder:
- “¿Esto proviene de un solo grupo de socios?”
- “¿Una ruta produce la mayoría de los rechazos?”
- “¿La mayoría de las quejas provienen de cuentas recién financiadas?”
- “¿Un grupo de símbolos está provocando el estrés del margen?”
La segmentación por cohorte es una forma práctica de evitar restricciones amplias e imprecisas que castigan el flujo bueno.
Un modelo simple de segmentación:
- recién financiadas (primeros 30 días)
- retail activo (volumen constante)
- VIP
- cohortes de socios (grupos de IB, afiliados)
- grupo de alta disputa (problemas repetidos)
“La escala se rompe cuando gestionas a todos de la misma manera, aunque el comportamiento no sea el mismo.”
Rastros de evidencia que reducen disputas y dolores de cumplimiento
El monitoreo no solo se trata de prevención. También se trata de la rapidez de la explicación.
Un “paquete mínimo de evidencia de ejecución” debe incluir:
- marca de tiempo del pedido y marca de tiempo de recibo
- instantánea de cotización al momento del pedido
- respuesta de ruta y centro
- marca de tiempo de llenado y desglose de latencia
- estado del margen al entrar
- diccionario de códigos de razón de rechazo
Si el soporte puede obtener esto rápidamente, las escalaciones disminuyen y el equipo deja de adivinar.
Un plan de implementación de 30 días que evita el caos
Puedes mejorar el monitoreo sin reconstruir toda tu pila. El truco es priorizar señales, propiedad y líneas base.
Semana 1: Líneas base y definiciones
- definir grupos de símbolos y sesiones
- líneas base de márgenes, rechazos, percentiles de latencia durante 14 días
- estandarizar códigos de razón de rechazo
Ssegunda semana: Monitor de márgenes más niveles de alerta
- implementar seguimiento p50 y p95 de márgenes por sesión
- definir niveles de alerta (informativa, acción, escalada)
- asignar responsables y expectativas de reconocimiento
Semana 3: Playbooks y simulacros
- escribir tres playbooks de una página (diferencial, rechazos, latencia)
- realizar un simulacro de mesa con soporte, operaciones y riesgo
- refinar los umbrales para reducir falsos positivos
Semana 4: Cohortes e informes
- agregar segmentación de cohortes y vistas a nivel de ruta
- crear una revisión semanal:
- incidentes
- causas raíz
- acciones y responsables
- ajustes de umbrales
- incidentes
El objetivo es una mejora constante, no un “lanzamiento de monitoreo” puntual.
Errores que sabotean los programas de monitoreo de liquidez
- Solo monitorear promedios y perderse los eventos extremos
- No hay líneas base de sesión, por lo que las alertas no tienen sentido
- Demasiadas alertas, lo que lleva a la fatiga y señales ignoradas
- Sin responsabilidad, por lo que la respuesta depende de quién está en línea
- Sin playbooks, por lo que cada incidente se convierte en una reunión
- Sin paquete de evidencia, por lo que las disputas se convierten en argumentos
Si solo arreglas una cosa, arregla las líneas base y la responsabilidad. Todo lo demás se construye sobre eso.
Próximo paso antes de la FAQ
Si deseas un monitoreo que realmente ayude, comienza con una línea base de 14 días para diferenciales (p50 y p95), rechazos y latencia p99 por sesión y grupo de símbolos. Luego construye un un monitor de márgenes que se correlaciona con picos de rechazos y obsolescencia de cotizaciones, y escribe tres playbooks de una página para que la respuesta sea consistente. Si compartes tus instrumentos más negociados, las horas de negociación más ocupadas y el tipo de queja más común, envía esa instantánea a tu equipo de operaciones y úsala para pilotar una tabla de alertas más ajustada y un paquete de evidencia que proteja ejecución de órdenes de trading y mejore velocidad y estabilidad del trading sin añadir ruido.
FAQ
¿Por qué importa monitorear todas las fuentes de liquidez?
Porque los problemas a menudo son aislados: un lugar amplía diferenciales, una ruta rechaza, una fuente se vuelve obsoleta. Sin visibilidad en todas las fuentes, los equipos reaccionan tarde o culpan al componente equivocado.
¿Qué debería monitorear un diferenciador aparte del diferencial actual?
Percentiles por sesión (p50 y p95), además de valores atípicos y duración. El objetivo es detectar un comportamiento anormal, no observar un número en movimiento.
¿Qué métrica de ejecución predice más fiablemente las quejas de los clientes?
Eventos extremos de deslizamiento y picos de rechazos. Los promedios pueden parecer bien mientras que el comportamiento extremo provoca la mayoría de las disputas y frustraciones.
¿Cómo se puede reducir la fatiga por alertas?
Usa líneas base de sesión, alerta solo sobre desviaciones sostenidas y clasifica las alertas por gravedad. Cada alerta debe tener un responsable y una lista de verificación de primeras acciones.
¿Un mejor monitoreo de la liquidez mejora automáticamente los rellenos?
Mejora la detección y respuesta, lo que reduce la duración e impacto de los incidentes. Mejores rellenos suelen venir de las acciones que tomas una vez que el monitoreo revela la causa.
¿Cuál es la evidencia mínima necesaria para resolver rápidamente una disputa de relleno?
Timestamps de la orden, instantánea de cotización, ruta de enrutamiento, respuesta del lugar, desglose de latencia y un diccionario claro de razones de rechazo si ocurrió un rechazo.